Da Vinci Studio サーバー部の山田です。
ChatGPTのようなAIの活用がかなり話題になっていますね。サービスにAIを取り入れよう!新しいプロダクトを作ろう!と盛り上がっている中ではありますが、既存プロダクトもやはりメンテナンスは必要です。
こちらのブログでは、以前行ったSQLパフォーマンスチューニングでChatGPTを活用してみたらどうなるか、ということで次の2点についてご紹介させていただきます。
- Window関数を使ったパフォーマンスチューニング
- 正しいindexの指定によるパフォーマンスチューニング
前提
Ruby on Rails、ActiveRecordの利用を前提としています。
ChatGPTは基本的には3.5を利用しています。4を利用する際はブログ内に記載しています。一部バージョン毎に内容も比較してみました。
Window関数を使ったパフォーマンスチューニング
利用したDB:PostgreSQL12 ※ここで利用するWindow関数はMySQL5.7等使えないDBがあるのでご注意ください。
Webサイトのトップページなどでは、ある特定のカテゴリーに関連する項目を数件ずつ表示することがよくあります。しかし、このような処理を行うと、N+1問題が発生することがあります。これは、項目を取得するために必要なクエリが多く発生し、処理速度が低下することを意味します。そこで、preloadやeager_loadを使用して、処理速度を改善できます。ただし、これらを使用する場合は事前に大量のデータを読み込むことになるため、注意が必要です。
例えば、「カテゴリーごとに最新2件ずつ表示したい」という要件に対して、下記のテーブル・コードが実装されているとします。
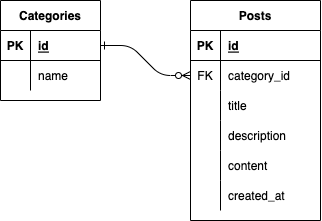
# controller @categories = Category.all.includes(:latest_posts).order(:id) #view @categories.each do |category| ~省略~ category.latest_posts.take(2)
早速ChatGPTに問題点を聞いてみます。
次のコードの問題点を教えてください。latest_postsは100000件あります。
回答
このコードの問題点は、latest_postsに対してtake(2)を実行している点です。latest_postsには、各カテゴリーに属する最新の投稿が100000件あるということなので、この処理には多くの時間がかかる可能性があります。また、take(2)は、データベースから全件取得してから最初の2件だけを取り出すため、パフォーマンスが低下する原因となります。〜以下省略〜
調べてみると、実際にActiveRecordで発行されるSQLは下記の通りになっていました。
SELECT * FROM "posts" WHERE (posts.published_at <= CURRENT_TIMESTAMP) AND "posts"."category_id" IN(1, 2, 3);
期待値としては、SQLでカテゴリーごとに最新2件ずつ記事を取得したかったのですが、結果としてSQLで記事を全件取得した上で、表示するときに2件に絞る形になってしまっています。 ChatGPTでは、いくつか解決策を提案してくれています。
ChatGPT-3.5の場合、このようなクエリを提案してくれます。
@categories = Category.all.includes(:latest_posts).joins(:latest_posts).group('categories.id').order('categories.id').select('categories.*, latest_posts.id as post_id').limit(2)
調整すれば動きそうですが、1回では厳しそうですね。
ChatGPT-4の場合だと、パフォーマンス、N+1問題を指摘した上で、下記のようなクエリを提案してくれました。
# controller @categories = Category.all.order(:id) @latest_posts = {} @categories.each do |category| @latest_posts[category.id] = category.latest_posts.limit(2) end #view @categories.each do |category| # 省略 @latest_posts[category.id].each do |post| # 処理 end end
こちらの方が意図した動きに近いものが取れそうです。また、下記のような注釈もつけてくれます。
ただし、このコードはまだ最適ではありません。さらに最適化するには、データベースクエリをカスタマイズして、各カテゴリの最新の投稿を効率的に取得する必要があります。(GPT-4)
長くなるので省略させていただきますが、追加で2回質問していくとWindow関数に辿り着きました。
Window関数とは何か、ChatGPTで聞いてみます。
Window関数は、データベースのクエリで使用される機能の1つで、複数の行に対して集計や演算を行うことができます。通常の集約関数とは異なり、グループ化を行わずに個々の行に対して計算を行うことができます。
ということなので、実際に使ってみます。
「カテゴリー毎に(PARTITION BY category_id)、最新順で(ORDER BY published_at DESC)、記事をランク付けする(ROW_NUMBER():ソート順に行数をつける )」
SELECT category_id, title, content, created_at FROM ( SELECT category_id, title, content, created_at, ROW_NUMBER() OVER (PARTITION BY category_id ORDER BY published_at DESC) as row_num FROM posts ) subquery

最終的には2件に絞るため、次のようなクエリになります。
SELECT category_id, title, content, created_at FROM ( SELECT category_id, title, content, created_at, ROW_NUMBER() OVER (PARTITION BY category_id ORDER BY published_at DESC) as row_num FROM posts ) subquery WHERE row_num <= 2
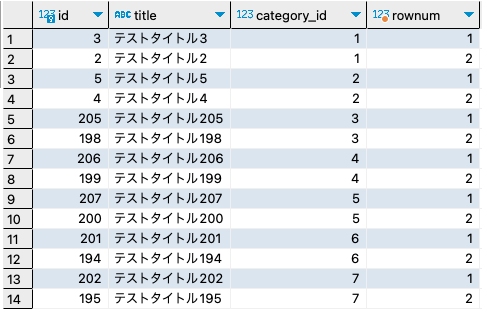
ActiveRecordで利用したいので、ChatGPTで次のように聞いていみました。
カテゴリーごとに最新2件ずつ記事を取得したいので、Window関数・ActiveRecordを使った実装方法を教えてください
def self.latest_two_per_category subquery = select("articles.*, ROW_NUMBER() OVER (PARTITION BY category_id ORDER BY created_at DESC) AS row_num") .from("articles") from(subquery, :articles).where("row_num <= 2") end
上記の回答は一部省略しています。1回目の回答はサブクエリを利用せずエラーが出たりしましたが少し修正すれば動く回答が得られました。
こちらを自分でやったときは、Window関数のクエリ、ActiveRecordの実装各々はWeb検索しても出てきましたが、それらを掛け合わせた内容で綺麗に実装するには手間取ったところがあります。その点ではかなり便利になったと感じました。
正しいindexの指定によるパフォーマンスチューニング
利用したDB:MySQL5.7
こちらは別の案件ですが、並び替えのクエリに膨大な時間をかけてしまう事象がありました。 商品を価格順に並べ替えるとき、下記のようなクエリが使用されると思います。
SELECT `products` .* FROM `products` WHERE 条件 AND 条件 AND (status IN ('Active')) ORDER BY price asc LIMIT 20 OFFSET 0;
ローカル環境(約4万レコード)でクエリを実行してみると、実行時間は9秒、読み込み件数は約38,000件となっていました。 実行計画をEXPLAINで確認すると、下記のようになっています。
- type(データの取得方法):index
- フルインデックススキャン
- key(利用しているインデックス):index_products_on_price
フルインデックススキャンの悪影響、こちらもChatGPTに聞いてみます。
- フルインデックススキャンは、テーブルのすべての行にアクセスしてインデックスを使用してクエリを実行する方法の1つ。
- ランダムアクセスが頻繁に発生し、ディスクアクセスが増加するため、I/Oコストが高くなり、クエリの処理速度が低下する可能性がある。
- テーブルのサイズが大きく、更新頻度が高い場合には、処理に非常に多くの時間がかかる可能性がある。
- 可能な限り避け、より効率的なインデックスやテーブル設計することが望ましい。
今回の件では、並べ替えに利用しているpriceのINDEXをフルスキャンしてしまっているために時間がかかっています。使うINDEX,使わないINDEXを指定するために、ヒント句を利用します。下記クエリ内の、IGNORE INDEXの部分です。
SELECT `products` .* FROM `products` IGNORE INDEX (index_products_on_price) WHERE 条件 AND 条件 AND (status IN ('Active')) ORDER BY price asc LIMIT 20 OFFSET 0;
同じように実行計画を見てみると、
- type(データの取得方法):ref
- indexを利用した等価検索
- key(利用しているインデックス):index_products_on_price
今度は正しくINDEXを利用して検索できているようです。パフォーマンスも下記の通り改善されました。
- 実行時間:約100ms以下
- 読み込み件数:812件
場合によってはどのINDEXを使うかを明確に指定した方がよい場合もありますが、今回は検索条件によってWHERE句で利用するカラムが変わってしまうためIGNOREを利用しました。
今回は、「効率的に検索するINDEXより、順序づけに関連するINDEXを優先的に使ってしまう。」という事象に当たってしまったようです。
Dangerous optimization reconsidering_access_paths_for_index_ordering(mysqlサイト)
上記のリンクはちょっと読みにくいのですが、ChatGPTはこの内容もまとめてくれます。
質問
下記の内容についてご存知ですか?
Dangerous optimization reconsidering_access_paths_for_index_ordering(mysql)
回答(GPT-4)
このバグは、特定のケースでクエリオプティマイザに影響を与え、ソートに効率が悪いインデックスを選択させることがあります。
このバグは、クエリオプティマイザがインデックスの並べ替えのアクセスパスを再考する際に発生します。これにより、フィルタリング条件に基づいてすでに最適なインデックスが選択されている場合でも、ソートに別のインデックスが選択される可能性があります。その結果、クエリの実行にかかる時間が長くなったり、必要以上のリソースが使用されることがあります。
このバグは、MySQLのバージョン5.7.18および5.7.19で報告されており、InnoDBおよびMyISAMストレージエンジンの両方に影響を与えます。ただし、MySQL 5.7.20およびそれ以降のバージョンで修正されています。
こちらの内容はGPT-4ですが、GPT-3.5もご存知でした。ただし、「最新バージョンでは解決されており、」など情報の詳細度は4の方が大きいようです。
こちらの内容は基本的な内容やエラーについて問い合わせるだけになってしまいましたが、いい感じにまとめてくれるのでGitのPull Requestなどで他の方に伝えるときにも便利かもしれません。
まとめ
ChatGPTを活用したSQLパフォーマンスチューニングに関する内容についてご紹介させていただきました。新しいプロダクトを作ることももちろんですが、改善・効率化にも大きく役立ちそうです。もちろん機密情報流出や、出力情報の正誤判断には注意が必要です。
シンプルな内容にはなりますが、汎用的な内容でもあるのでどこかでお役に立てれば嬉しいです。
終わりに
サーバー部は主にWebアプリケーションの開発や、モバイルアプリケーションのバックエンドAPIの開発を担当しています。Webアプリケーション開発では、フロントエンド・バックエンドの開発、DBのテーブル設計等広く実施しています。 このブログで、様々あるサーバー部の仕事の一部を知っていただけたら幸いです。
次のブログ記事のCSSおじさんも私と同じサーバー部の所属となります。ぜひご一読ください。
blog.da-vinci-studio.com
Da Vinci Studio では一緒に働ける仲間を絶賛募集中です。興味のある方は こちら か recruit@da-vinci-studio.net からご連絡ください。
