Da Vinci Studio サーバー部の吉延です。今回は社内ドキュメント管理ツールで行った検索機能改善の方法について説明します。
背景
くふうグループ内では社内ドキュメント管理ツールとして Da Vinci Studio が自社プロダクトとして開発している kajero (エスペラント語でノートと言う意味) が使用されています。kajero では全文検索エンジンとして Amazon OpenSearch Service を使用しており、社内から出る様々な要望を聞きながら機能改善をしています。ある日採用に関わる方から「'ジョブポスティング'というワードを'ジョブポス'で引っかかるようになれば嬉しい」という要望がありました。そこで今回はその要望を満たすために行ったシノニムの追加による検索機能改善について書こうと思います。
シノニムとは
シノニムは日本語で類義語という意味でワードをグルーピングしてそれらのワードであればどのワードでもヒットさせるようにします。今回の例でいうと ジョブポスティング・ジョブポス・ジョブ がそれぞれのワードでヒットされるようにします。
シノニムの追加の方法について
シノニムを追加する方法としてインデックスベースとファイルベースの2種類あります。 インデックスベースはインデックスに直接シノニムを書き込む方法です。一方でファイルベースはシノニムをテキストファイルに書き込み、そのファイルをインデックスに登録する方法です。インデックスベースは辞書の管理が大変でしたが、2020年4月21日から Amazon OpenSearch Service でファイルベースのシノニムユーザー辞書などに対応するカスタムパッケージが利用可能になっている(Amazon Elasticsearch Service がカスタム辞書ファイルをサポート開始)ということだったので今回はファイルベースでシノニムを追加しました。
辞書について
まず .txt 形式 シノニムファイルを用意します。
シノニムの書き方は以下のように類義語をカンマ(,)区切りで記入します。
ジョブポスティング, ジョブポス, ジョブ
登録方法
続いて上の工程で作成したファイルを対象の Amazon Simple Cloud Storage(AWS S3) バケットにアップロードします。 次に Amazon OpenSearch Service にアクセスし、パッケージのページからパッケージのインポートを行います。パッケージとは AWS S3 にアップロードしたシノニムファイルのことです。
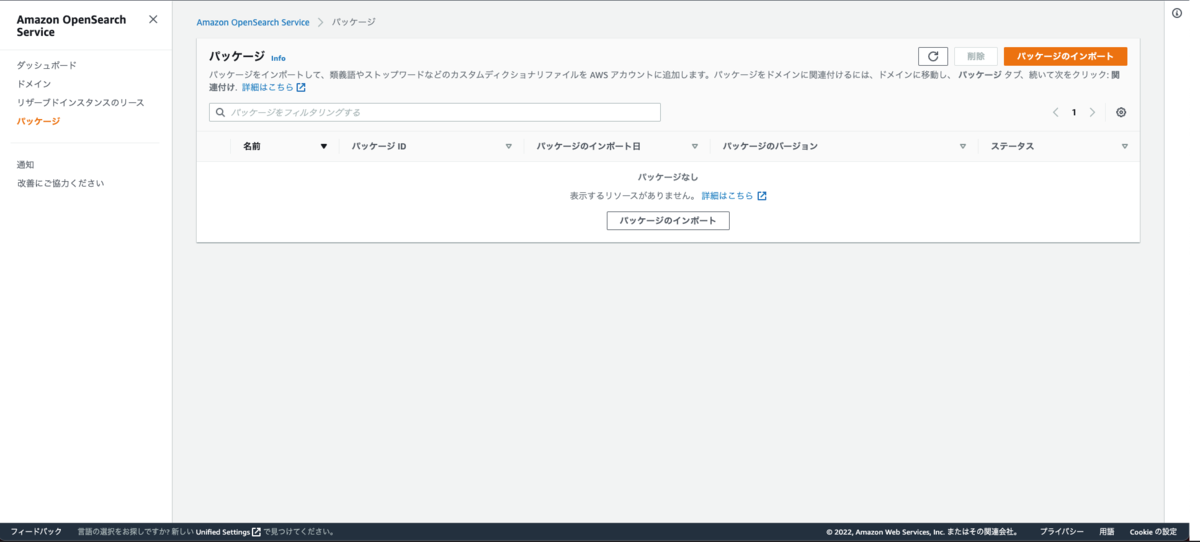
インポートが完了すると、一覧画面に登録したパッケージの情報が追加されます。 パッケージの情報ができたらパッケージの詳細ページからパッケージとドメインの関連付けを行います。次に「ドメインへの関連付け」から関連付けたいドメインを選択し関連付けます。最後に関連付けられたドメイン情報から関連付けのステータスがアクティブになっていることを確認します。リファレンスパスは後ほどインデックスの設定で使用します。
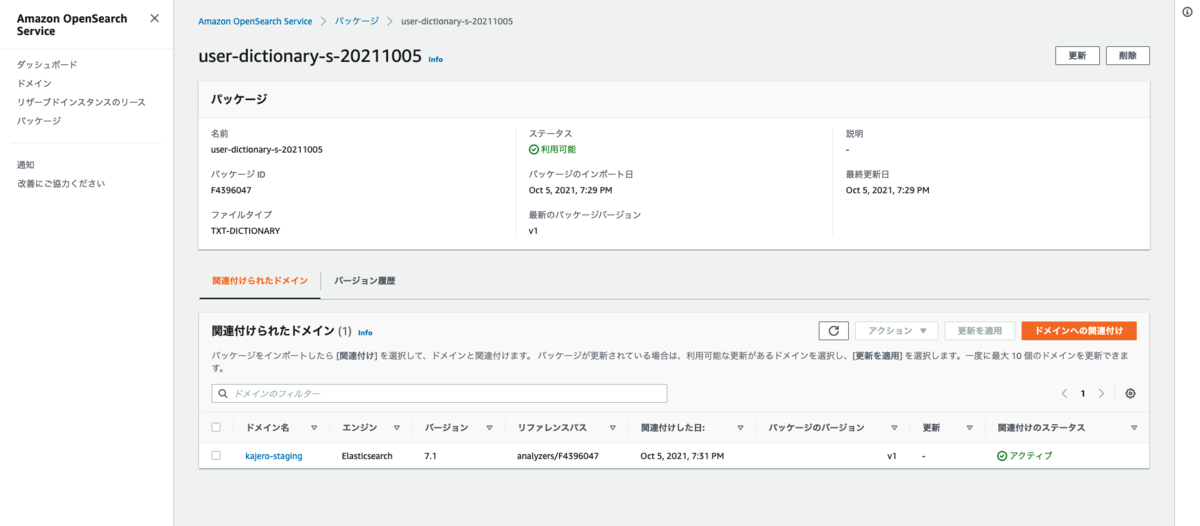
インデックスの設定
まずシノニムを適用していないインデックスで検索結果がどのようなものになるか確認してみます。画像のようなインデックスを作成し、
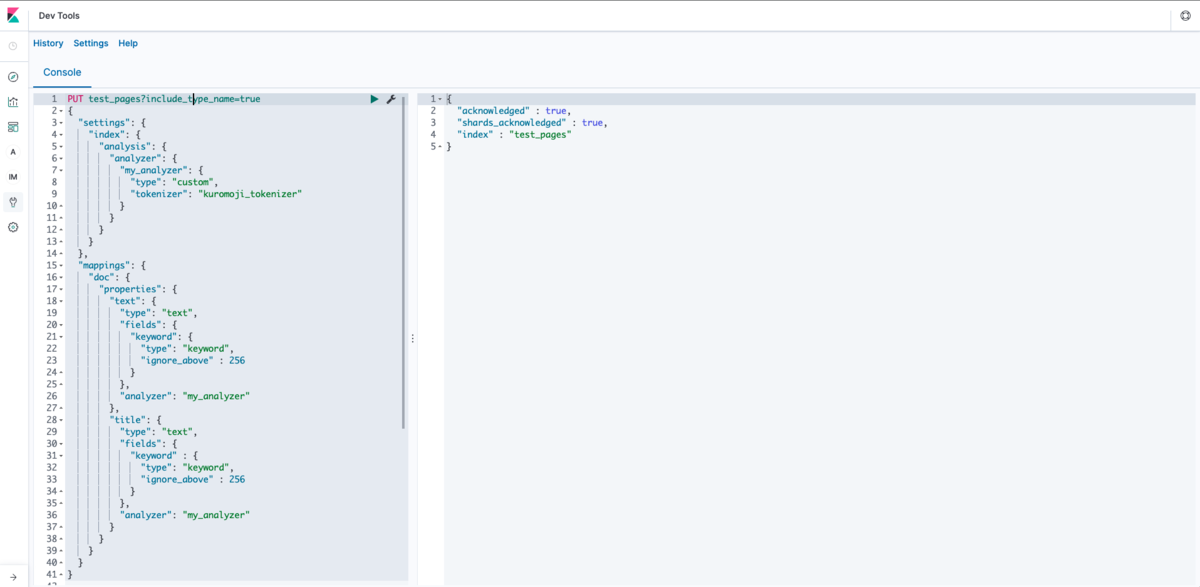
ジョブポスティング、ジョブポス、ジョブの文字列が書かれているドキュメントを用意してみます。
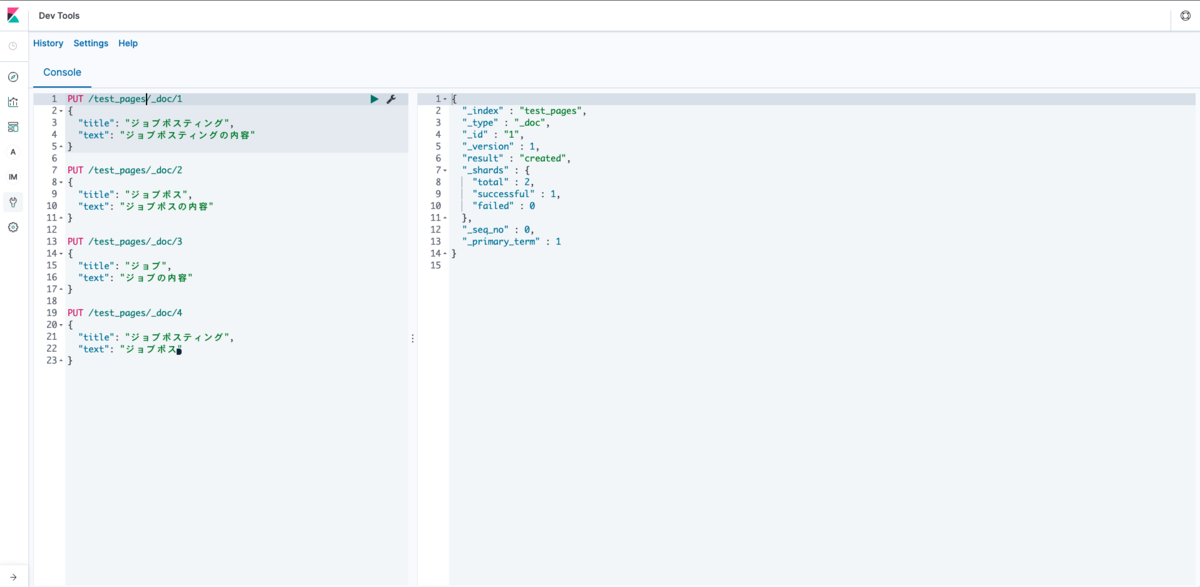
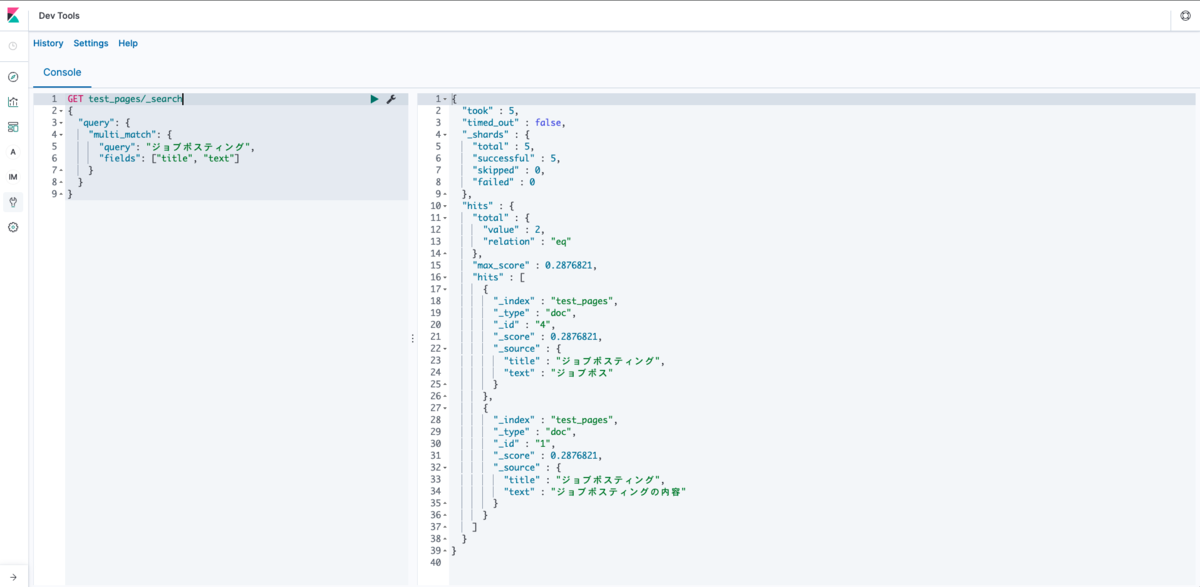
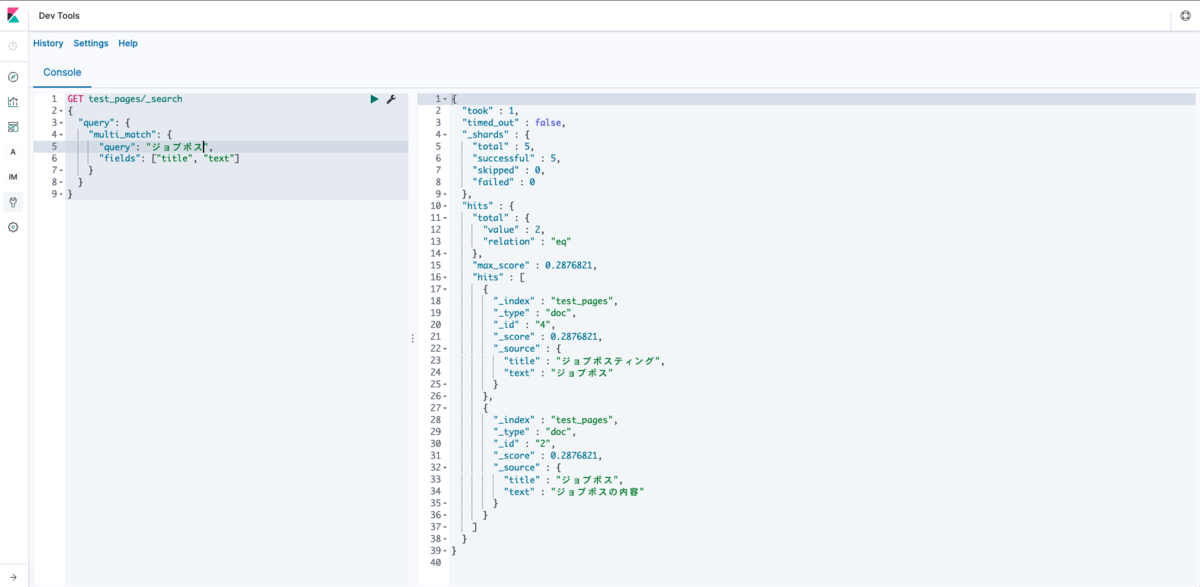
検索するとジョブポスティングのクエリの場合はジョブポスが書かれたドキュメントがヒットしないことがわかります。逆もまた然りです。
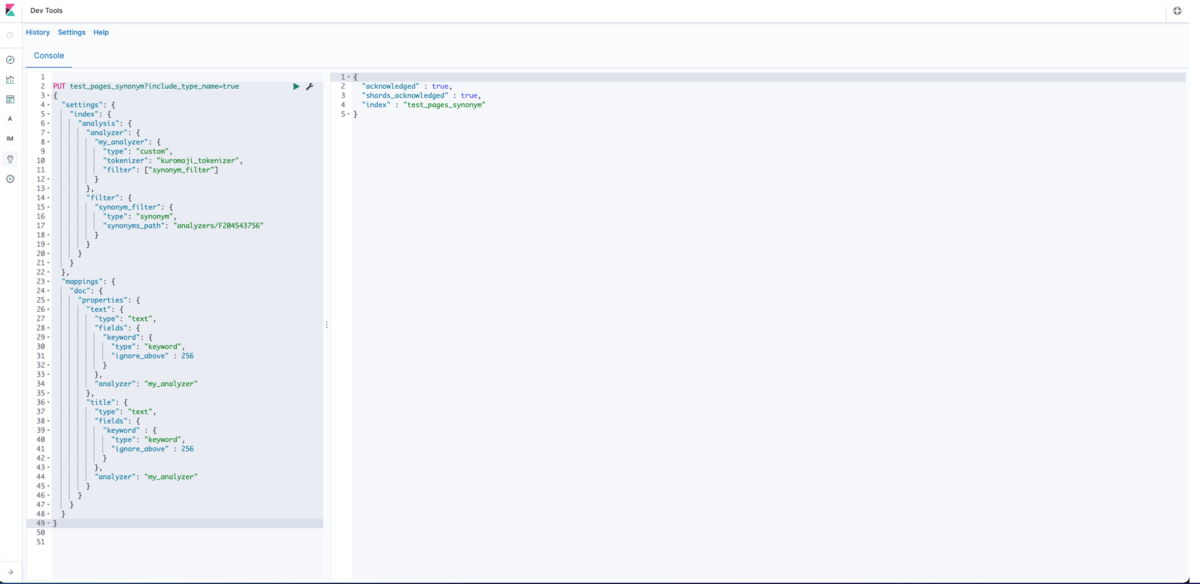
それでは先程設定したパッケージを紐付けたインデックスを作成してみます。 synonyms_path には上記で作成したリファレンスパスを記述します。 シノニムの詳しい設定方法は Synonym token filter を参照してください。
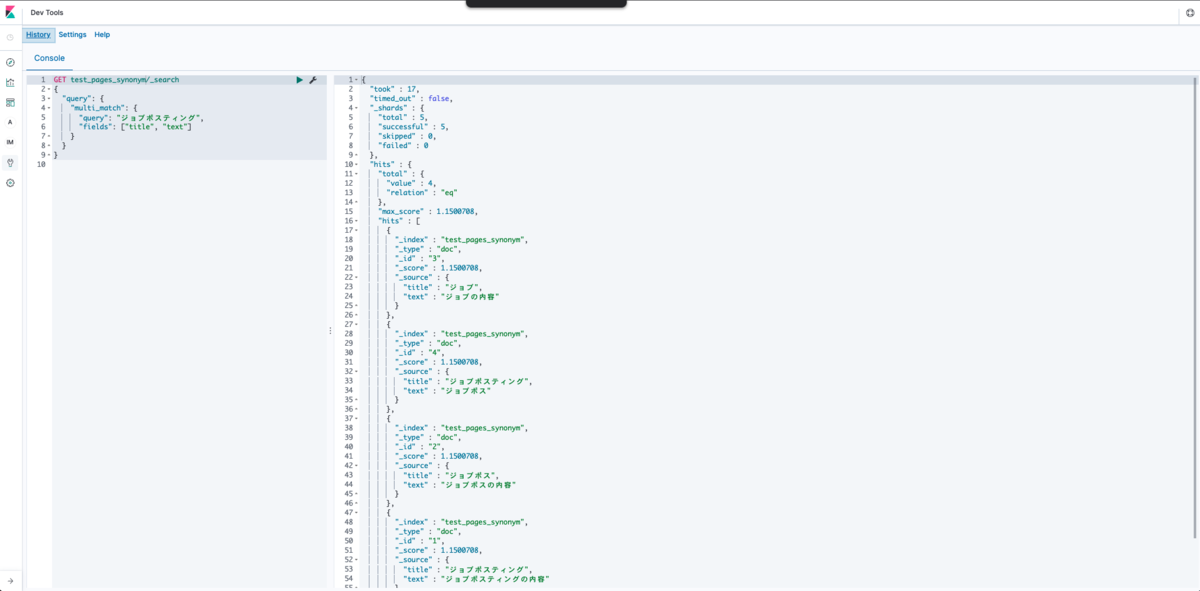
検索してみると、ジョブポスティングというクエリでジョブポスやジョブが書かれたドキュメントがヒットするようになりました!
インデックスは更新できないので、インデックスの設定を変更する場合はインデックスを新規作成する必要があります。すなわち、シノニムの追加や内容更新をする場合は、インデックスを新規作成する必要があります。
インデックスの作成は上記の方法で行ったので、残り必要な工程は
- 元インデックスから新インデックスにデータをコピーする(ドキュメントの再インデックス)
- webアプリケーション側で新インデックスを参照するようにする
を行う必要があります。
ドキュメントの再インデックス
ドキュメントの再インデックスには時間がかかる場合があり、その間に登録されたドキュメントが新インデックスに登録されないという事態をなるべく避けるため、サービスログ等からアクセス頻度が低い時間帯に行う必要がありますので注意してください。ドキュメントの再インデックスは以下のようなリクエストで行うことができます。 source には元インデックス名、 dest には新インデックス名を指定します。詳しくは Reindex API を参照してください。
POST _reindex
{
"source": {
"index": "pages_production"
},
"dest": {
"index": "pages_production_20220620"
}
}
これで後は参照するインデックスを変更すれば作業は完了になりますが、インデックスを更新する際にデータ破損や障害発生によりインデックスの切り替えが失敗するリスクを回避するためスナップショットからの復元方法も事前に調べておくとよいです。Amazon OpenSearch Service ではスナップショットを2週間前まで1時間ごとに自動で取得してくれています。下記のリクエストでスナップショットのデータを確認できます。
GET _snapshot/cs-automated/_all
上記の結果から復元したい時点のスナップショットデータと復元したいインデックス名を指定することで復元できます。
POST /_snapshot/cs-automated/スナップショットデータ/_restore
{
"indices": 復元したいインデックス名
}
終わりに
今回は初回ということもあって手動でシノニムを追加しました。今後はシノニムの内容の増加やインデックスの作成や再インデックス、インデックスの切り替えなどが自動化できるとより使いやすいシステムになっていくと思っています。
Da Vinci Studio では一緒に働ける仲間を絶賛募集中です。興味のある方は こちら か recruit@da-vinci-studio.net までご連絡ください。